This is the second part of a three-part series for a large international client that partnered with our team at LaunchPad Lab for their digital transformation. In this part, we will discuss the considerations for the client’s complex data architecture, and the tradeoffs of different data syncing approaches.
If you are interested in understanding more of the client background from this use case and the initial technical state of the project, read part one of the three-part series.
Syncing Data
In part one, we described the client’s goal of integrating Salesforce with their existing and new custom applications to develop a comprehensive view of their customers. As part of that effort, we first migrated the client’s existing database tables from MySQL to Postgres. Those tables lived under a schema namespace of “portal”. As part of the new applications we were building, we introduced new database tables, which were added to the conventional Rails schema namespace of “public”.
Additionally, it’s important to remember that the system architecture included three separate “clients”, or users, of the database:
-
- Legacy PHP app
- LaunchPad Lab-built Rails API
- Salesforce instance via Heroku Connect
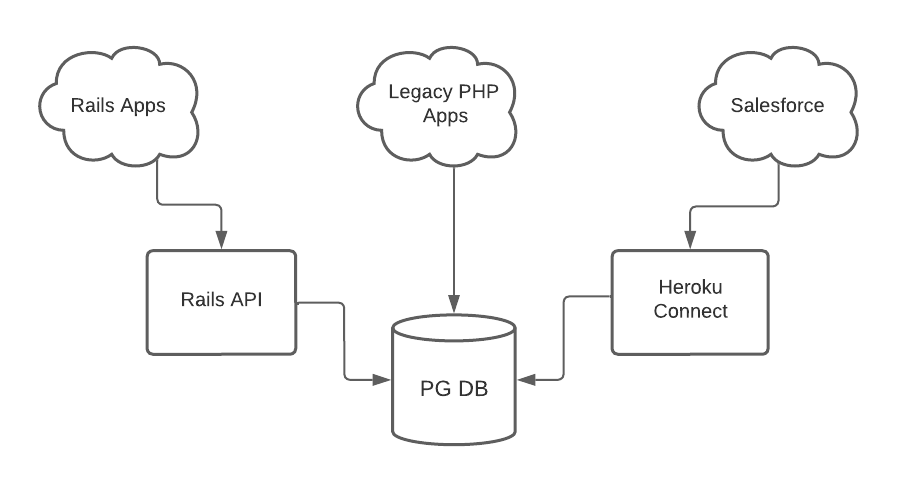
With the infrastructure in place to connect these disparate systems, we could tackle the technical and business logic of keeping the data in each system in sync with each other. When designing a data-syncing architecture, there are several important factors to consider:
-
- What data is syncing and what is the data’s path between systems
- How data syncing is tracked, verified, and protected
- What dependencies and conflicts exist between data entities
- How data sync failures are surfaced and managed
With Heroku Connect, you are able to support the answers to many of the questions above out of the box. The tool provides a simple interface for selecting which Salesforce objects and which fields on those objects to sync; it provides logging tools to track sync statuses and failures; and manages the timing of syncs, providing options for real-time syncing.
When you add Heroku Connect to an application and select the objects and their fields to sync, Heroku Connect runs migrations on the Postgres database for those objects. That is, it creates a table for each Salesforce object selected with the chosen fields. These tables are placed in a “salesforce” schema in the database.
Creating these analogous tables in the database is what drives the bi-directional sync aspect of Heroku Connect. When interacting with those tables under the “salesforce” schema directly (e.g., making an update or creating a new record), Heroku Connect pushes those changes out to Salesforce. In return, Heroku Connect listens for, or polls for, changes in Salesforce to bring those updates back into Postgres and update the records on those tables it created.
The problem faced in this project was that in reality, we now had objects under three separate schemas we needed to keep in sync. Since we were not removing any pre-existing tables, a change in the original portals.user table would have to carry over to the Salesforce version of table, e.g., salesforce.accounts, in order for Heroku Connect to ultimately propagate the changes to Salesforce.
This problem is very common in data syncing, where you actually have disparate sets of data that need to align at any point in time. While Heroku Connect made it easy to propagate changes out to Salesforce, a big task that doesn’t need to be reworked, we just had to solve for how to align those changes between the different database schemas.
Capturing and Handling Data Updates
There are several ways in an application to know how and when data changes, and then perform subsequent work with those changes. As described above, Heroku Connect manages the how and when between the Salesforce instance and the Postgres salesforce schema. However, we also needed to know how and when data changed in the portal and public schemas.
Some common strategies to address this problem include explicitly triggering work after executing code to update a record (i.e., a “callback”), requesting data to determine changes (i.e., “polling”), and using an event-based system (e.g., subscribing to notifications). As we developed this data-syncing strategy, we iterated through these different approaches until we found one that best met our constraints.
(Rails) Callbacks
In Rails, a common feature is callbacks around database operations, such as before creating a record or after updating a record with ActiveRecord, Rails’ Object Relational Mapping (ORM) framework. A callback is a function that is invoked from another function to complete a process. These Rails callbacks are easy to use and can be useful in data syncing. You include the callback in the ActiveRecord class for your table, and Rails will execute the code after the specified transaction (e.g., an after_update callback will fire after calling user.update(first_name: 'Mary')). For example, after a User record is updated in the Rails app, you could call some other process to update the analogous Salesforce::Account record that relates to that User record.
This is the first approach we tried, as it was familiar and straightforward. This worked well when updates to the app were made through the Rails API, which was leveraging ActiveRecord and seamlessly invoked the callbacks. However, we quickly realized that since not all consumers of the data connected through the Rails API, these callbacks had limited accessibility.
As described above, the existing PHP actually connects directly to the Postgres database, rather than making calls through the Rails API. Additionally, Heroku Connect does the same thing, making direct SQL statements to the database, rather than routing through the custom app’s specific internals or application logic. As a result, database transactions through either of those sources would never reach these callbacks written at the application layer.
Polling
Another common data syncing strategy is to “poll” for changes. This can be implemented in a variety of ways, but the idea is to regularly check the database for changes. This approach could work for all consumers of the database, as we would be intentionally working with the data directly.
To do so in a Rails app, you might write a task to periodically query the database for new records, using the creation timestamp, or for updated records using the update timestamp. For example, we might write a query to return all portal.users records updated in the previous second, or all salesforce.account records updated in the previous second, and propagate the changes that occurred to the analogous table.
While there are opportunities to optimize these queries, over time, and with as large of datasets as we had, these queries could become very expensive. Additionally, using those timestamps as proxies for changes felt brittle. Although there are several helpful tools and programs to run these checks often, even down to the second, implementing each step by hand felt unreliable.
We realized at this point that what we were trying to accomplish was to listen for changes to the database (reactively instead of proactively with polling), and be able to pass those changes off to our custom syncing logic (much like a callback would). We discovered just what we were looking for, in the way of Postgres triggers and its listen and notify functions.
Postgres Triggers with Listen / Notify
Postgres triggers are essentially callbacks but at the database level. The listen and notify functions provide a way to capture and broadcast messages from the database outward, much like a publish/subscribe scheme. For example, we could add triggers to the portal.users table that broadcast a notification to an update_user channel. A listener listening to update_user would receive the payload, or data involved in the update transaction, and we could work with that payload to update the analogous salesforce.account record.
It turns out, this is much of what Heroku Connect uses under the hood as well. It uses Salesforce’s streaming API (which is much like a publish/subscribe or listen/notify scheme) and uses triggers to perform resulting changes in the database.
The benefits of these Postgres capabilities meant that it could be used for all consumers of the database, but unlike polling, we could rely on the database to tell us exactly what and when something changed, in the instance the change occurred.
The only downside really was that implementing elements of this strategy required some more nuanced SQL, but we were able to limit the SQL to using these capabilities, and still keep the core of the business logic for data syncing in Ruby.

Once we explored this option, we proceeded to implement triggers and the listen and notify functions across the tables that would be synced, and the additional custom syncing logic needed for those tables.
In part three of our Integrating Salesforce With a Legacy System series, LaunchPad Lab will cover these implementation steps, and the additional considerations of the other key elements of a robust data syncing strategy. Stay tuned to learn more!




